
Verissimo Monthly - May 2025
The Unreliability of LLMs & What Lies Ahead

Thoughts on Investing and Starting Up
It’s been a big week in AI. Google, OpenAI, and Anthropic all had major releases, and one clear throughline was the push toward increasingly autonomous coding agents. So we figured this was the perfect moment to talk about how unreliable Large Language Models (LLMs) are as a base technology, and what that means for builders trying to work with them.
Unreliability is the core bottleneck to unlocking the full power of LLMs. For all the deserved excitement around LLMs, most users still engage with them only occasionally. Daily active use remains comparatively low. You could read that as limited utility or slow dispersion, but we think a major contributor is unreliability. When a system can’t be trusted to work consistently, its real-world utility collapses. It’s no coincidence that the clearest value from LLMs so far has come from code generation, where outputs are not only useful, but highly verifiable. You can run the code, test it, compile it. It either works or it doesn’t. And the product it supports—software—is deterministic by design.
This piece explores:
The core challenge: LLMs are fundamentally unreliable, a characteristic we believe is unlikely to change soon.
Implications for builders: Success in building AI-powered products doesn’t come from waiting for perfect models, but rather from from building around their inherent variance.
Framework: We outline four distinct approaches builders can take to manage variance. We'll map the core characteristics of each, offering a clearer lens for assessing whether a given team's capabilities and chosen strategy align.
LLMs are temperamental
We’ve spent the past few years closely tracking the LLM space, following the research, watching how companies are deploying them, how users interact with them, and using the models extensively ourselves. These observations have made one thing abundantly clear: large language models are fundamentally unreliable.
Their outputs often deviate significantly from the intended result.
This unreliability is persistent. It might be low in some cases, but it never fully disappears, and it’s largely unpredictable ahead of time.
Even in the most constrained, well-defined tasks, LLM behavior is not deterministic.
Crucially, when LLMs are asked to perform tasks that involve any kind of real agency—multi-step actions, tool use, autonomy—these reliability issues get far worse. Failure rates spike to levels that make these systems unusable in real-world scenarios.
We believe these core reliability dynamics of LLMs aren’t likely to change meaningfully in the short to medium term.
Some concrete findings
LLMs hallucinate—that is, they generate incorrect outputs. The most reputable benchmarks we have, including those used by leading labs in their model cards, indicate that baseline hallucination rates, in scenarios where the model relies on its “own memory” (a useful proxy for many real-world failure modes), are around 50% even for the best models.

There are narrow usage patterns, e.g., when the answer is explicitly included in the prompt where error rates can drop to ~1%, but this is fragile: these rates are heavily dependent on the type of question, and even then, it still falls well short of software-grade reliability.

This is a case where hallucinations really shouldn't have happened, the correct context was provided, the chatbot merely needed to format a citation Theoretical work indicates that a non-zero probability of hallucination is an inherent and unavoidable characteristic of LLMs.
As avid users, we can attest firsthand: while skill can help mitigate failures, it is nowhere near sufficient for full reliability.


These reliability issues get worse when LLMs act as agents, systems that must orchestrate tools, interact with software, and carry out multi-step tasks. Empirical results across a range of the most rigorously constructed agent evaluation benchmarks show agentic AI performance well below human levels, and worse, the rate and nature of these failures (their unpredictability and chance that they can happen at “any time”) make these systems unusable.
Code generation is one of the most mature use cases for LLMs—and even here, the same reliability issues persist. Widely cited research from METR, arguably the most thorough study of LLM code performance to date, suggests that reaching 99% correctness is only feasible for code a human could write in under a minute. There are caveats (including how human baselines are estimated), but the core insight holds: even with strong feedback signals and tightly scoped tasks, LLMs still make small, consequential mistakes—making truly high-accuracy code output surprisingly difficult to achieve.
LLMs are highly input-sensitive. Minor, even purely cosmetic, changes to prompts can produce wildly different outputs, undermining predictability and confidence in test results
This ties back to the core strength of LLMs: their flexibility. You don’t need to know the exact input in advance, that’s why we use them. But it also means that performance on “in-distribution” test cases doesn’t tell you much about how the model will perform in the wild.
Alignment. We won’t dive into the full complexity of the alignment discussion here—it’s a deep and important topic—but the basic idea is this: alignment is the discipline concerned with making sure that models behave, at a high level, the way we intend them to. It’s what tries to prevent scenarios where an LLM blackmails its developer to avoid being shut off, or gives users instructions on how to build bioweapons. It’s a critical area of research, and very much not a solved one. Beyond just illustrating how fundamentally opaque these systems still are, unsolved alignment directly impacts the viability of agentic LLM use cases. But as noted, this is a topic worthy of its own deep dive, so we’ll leave it at that for now.
Projecting forward
Forecasting AI progress is notoriously difficult, especially in a domain evolving this quickly. That said, we have reason to believe that the core reliability dynamics of LLMs aren’t likely to change meaningfully in the short to medium term.
Here’s why:
A key reason we believe these reliability issues will persist is the way LLM errors interact with task complexity. Our own observations (and interpretations of much of the available research and empirical findings), suggest that LLM failure modes compound with task length in ways that exceed typical human error patterns. This tendency for AI errors to multiply and cascade will, we suspect, remain a fundamental barrier for truly reliable agentic systems for the foreseeable future.
The fact that no LLM use case has demonstrated true determinism in real-world applications is significant. It strongly supports the theoretical arguments discussed earlier, which posit that hallucinations are an unavoidable, and likely unsolvable, aspect of current LLM architectures.
A striking example of LLMs' operational opacity comes from Anthropic's research, illustrated by how a model might calculate 36+59=95. Internally, it uses a sophisticated, multi-path strategy, approximating the sum with one heuristic while precisely determining the final digit with another. Yet, if asked to explain its calculation, the LLM describes the standard 'carry the one' algorithm taught to humans. This suggests the model lacks the mechanism to introspect and articulate the actual computational path it took. This inability to reflect post hoc—even to itself—underscores the black-box nature of LLMs. While speculative, we suspect this missing self-awareness contributes to their unreliability.
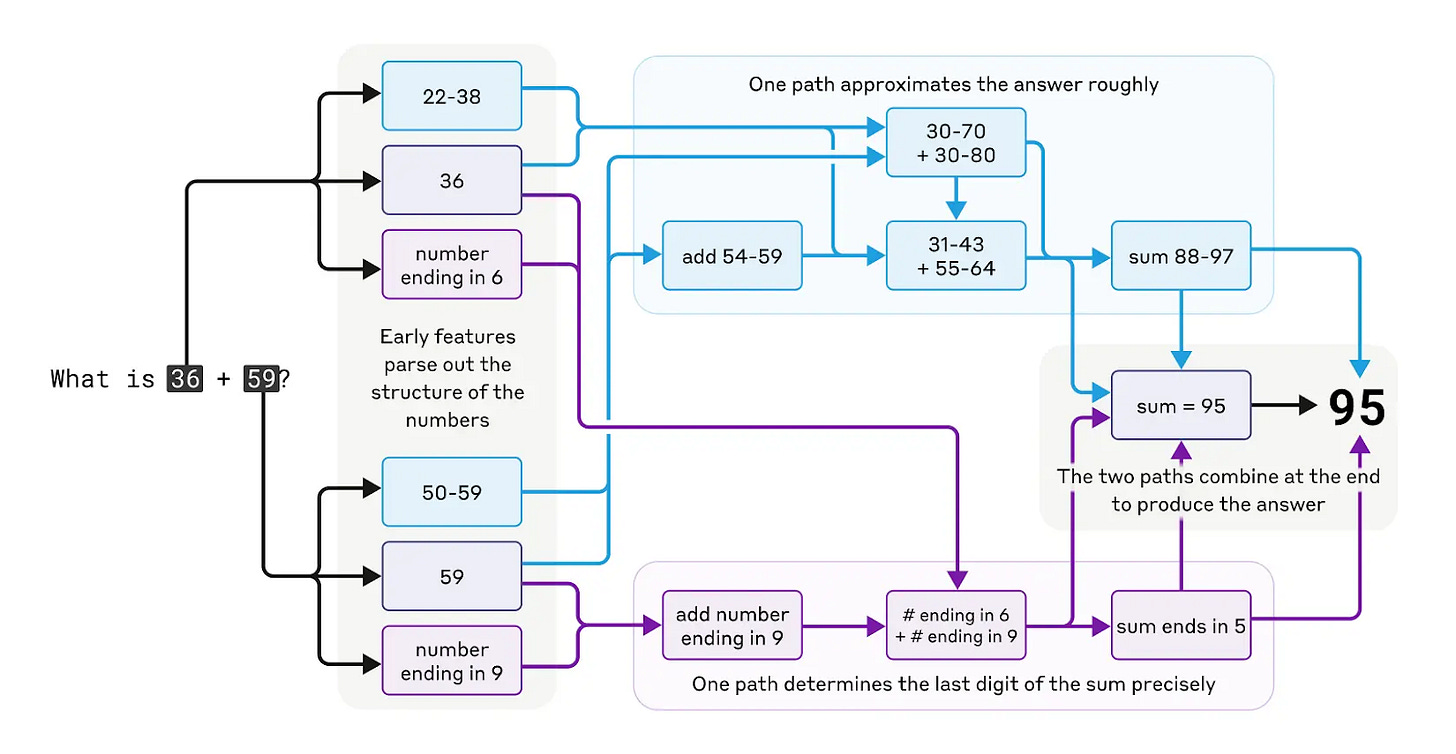
“Claude seems to be unaware of the sophisticated "mental math" strategies that it learned during training. If you ask how it figured out that 36+59 is 95, it describes the standard algorithm involving carrying the 1” The jaggedness of AI capabilities remains a major driver of unreliability. Models can demonstrate superhuman performance on advanced mathematics, yet still fail spectacularly on basic arithmetic. This inconsistency—seen across many domains—makes complex, multi-step tasks especially fragile: a single failure in an otherwise simple step the model happens to be bad at can drastically increase the overall error rate.


What this means for developers
We see two strategic tracks for building around LLM variance—(1) systems that operate without user verification, and (2) systems that manage verification explicitly. Each further breaks down into two distinct approaches.
Autonomy
Determinism
Accurate enough
Human in the loop
End-user verification
Verification at the provider level
These paths differ significantly in their strengths, the demands they place on development teams, and the sources of competitive advantage they offer. The following sections will unpack each one in turn.
1. Autonomy
This first broad strategy focuses on creating systems where the AI's output is intended to be used directly, without an explicit verification step by the end-user for each instance.
This includes systems that incorporate internal exception handling, where the system itself can detect inputs or scenarios it cannot process to the required standard of reliability and then gracefully manage these exceptions (e.g., by flagging them, routing to a different process, or informing the user it cannot proceed). The key concept here is allowing the system to 'run without babysitting', requiring additional capacity for when the system flags exceptions (usually means you need manpower) doesn't change this underlying dynamic.
This is the only category that enables fully autonomous usage, systems that can operate without human intervention. That makes it arguably the highest-margin path, with the clearest ROI story: either an existing process becomes faster, cheaper, and more scalable, or a new one becomes viable, and in both cases, the value is easy to measure. You can point to what the system does, what it improves, and what it costs.
This can be pursued in several ways:
1.A. Determinism
The aim here is to engineer an LLM-based system that, for all practical purposes, achieves complete determinism, mirroring the reliability of traditional software. Realizing this requires a system capable of exhaustively testing its outputs against rigorous criteria and, critically, remediating nearly all conceivable LLM-generated issues. Companies like Skyramp, focusing on deterministic AI for test generation, are exploring aspects of this space.
In practice, attaining this level of comprehensive determinism is extraordinarily challenging. It necessitates absolute confidence in having identified and addressed all potential edge cases and failure modes, a feat few if any have achieved in practice.
What defines this approach
This approach demands deep AI technical expertise. Getting an LLM-based system to behave deterministically is extremely hard, and being confident that it actually does requires a sophisticated understanding of how and where LLMs can fail. Unless the problem is already widely solved, teams must be able to both achieve high accuracy and rigorously validate it across edge cases.
Such a system likely requires a very sophisticated engineering layer, IP-worthy at that, this dynamic serves as a moat from both “models getting better" and competitors.
This does mean that there are likely serious demands for quality engineering talent as well, and depending on specifics, specialized talent (who else has experience in thinking about a system’s weak points?).
Your customer needs to trust you, really trust you that your tech does what it says it does, earning their trust may not be easy, but if you do, that is another source of competitive advantage.
1.B. Accurate enough
This path focuses on achieving a level of accuracy that is 'good enough' for a particular application where direct, instance-by-instance user verification is not part of the primary workflow, and occasional errors are within acceptable tolerance.
A critical requirement is achieving and validating a high degree of confidence that you have thoroughly accounted for all significant edge cases and the varied ways your LLM product can fail within the specific operational context.
Examples:
An AI classifier designed for very large, unstructured datasets, used for broad-based trend analysis. Here, occasional misclassifications can be tolerated as they are unlikely to skew the overall insights significantly.
Automated structured data extraction from documents (like invoices or forms), where the system achieves a high enough accuracy for direct use in downstream processes, with the understanding that a very small residual error rate is acceptable.
AI-powered note-takers for meetings. In many common usage patterns, there's no explicit human check on the generated notes. The underlying logic is often that notes with minor errors or omissions still offer greater utility than the alternatives of laborious manual note-taking or having no record at all.
What defines this approach:
For this strategy, it's critical to deeply analyze the user's workflow and the actual consequences of different AI failure modes (e.g., overgeneralization vs. complete fabrication, missed information vs. incorrect information). This involves an in-depth mapping of how various errors will impact the user's objectives and risk exposure. Crucially, developers must recognize that users themselves can be poor judges of these risks or may be overly trusting, as evidenced by ongoing issues like professionals misusing LLMs in critical fields despite widely known failure patterns (e.g., at least 20 cases of legal decisions where AI produced hallucinations just this month, despite hallucinations in law being a high-profile failure mode for years). The onus is on the product team to anticipate these issues, understand the true (not just stated) risk tolerance, and design accordingly, rather than solely relying on users to self-regulate their trust.
While perhaps less demanding than striving for proper determinism, it still requires strong enough AI skills to know what accuracy actually means in context, how to measure it, interpret it, and design around it.
For this strategy, the central aspect of product design is ensuring the product's core AI performance (its accuracy and reliability) is properly calibrated. While usability is always a factor, it's secondary here to achieving the target performance level.
Customers must trust the product's defined level of accuracy. This requires demonstrating consistent performance within those bounds, which can then become a key differentiator and competitive moat.
2. Human in the loop
Unlike approaches that strive to engineer out all AI variance, the second broad strategy for LLM product development accepts a degree of inherent model variability and focuses on managing its impact by integrating human verification into the process.
2.A. End-user verification
This common approach involves creating products where the end-user directly reviews, validates, and potentially corrects the AI's output as part of their workflow. To succeed, the value proposition must clearly justify the user's verification effort; the AI's assistance, even if imperfect, must be preferable to alternatives.
Examples
Search & discovery tools (e.g., web search, shopping search): Users often don't need every possible correct answer and can tolerate some irrelevant results if the tool quickly surfaces useful or intriguing information.
Information triage (e.g., "important document" finders in email): An AI might flag potentially missed invoices or critical communications. The user quickly verifies if the flagged items are indeed relevant, a task easier than manually sifting through everything.
Powerful general-purpose chatbots: LLMs via the chat interface are so broadly capable that users find ways to derive utility despite needing to critically evaluate responses and manage occasional errors.
"Copilot" paradigms (e.g., coding assistants like Cursor, legal tools like Harvey, etc.): The AI generates drafts or suggestions (code, legal clauses, analyses), and the expert user, who is "in the loop" at the right time, can quickly identify and correct issues.
Creative “content generation”: These are the canonical examples. Users can easily assess if the output’s style and basic coherence are suitable.
What defines this approach
Workflow augmentation: These products almost always enhance a specific user persona’s workflow rather than fully automating a standalone function (there’s also a small class of “alerting” use cases, but we assess that category to be relatively limited). This stems directly from the need for human verification: when humans are in the loop, they’re usually using the AI to do their job better, not babysitting it. In other words, the AI augments the human, not the other way around. While you can design a system where a human simply verifies AI outputs, that pattern rarely proves compelling in practice. The output has to be so valuable that it justifies paying someone to check it, and most applications don’t clear that bar.
Ceiling more than floor: Since this approach often involves users adopting new ways of working, the "ceiling" of value, the significant benefit derived from the AI's best or most insightful contributions, must be exceptionally high. This potential for substantial gains (e.g., speed, unique insights, quality improvements) is instrumental in justifying a change in work pattern and earn the user's verification effort. The focus is less on average AI accuracy ("floor") and more on the transformative potential of the AI's peak contributions.
Usability is central: Since user interaction and verification are integral, nailing the UI/UX for verification, correction, and seamless integration into the user's existing or new workflow is vital. Quality of user experience is then the primary differentiator and source of competitive advantage.
Designed for verifiability: A central characteristic is the design of AI outputs that are easily and reliably verifiable by the intended skilled end-user. This involves careful consideration of information presentation, the nature of the AI’s output, and ensuring the right user is targeted (e.g., AI accounting tools for accountants who can vet the suggestions).
2.B. Verification at the provider level
This distinct model places the responsibility for verification and ensuring the quality of the final output squarely on the product or service provider. This involves the provider's own internal human review processes, often working in concert with AI and specialized software to deliver a "done-for-you," result. From the customer's perspective, the AI's imperfections are handled "behind the curtain."
The end-user perceives this as an "AI-powered service". Usually, this involves the provider taking over a specific, often narrow, function previously handled by the client, fulfilling it in a third-party services style. The client receives a completed task or a digestible deliverable, effectively outsourcing the complexity of managing the AI and its potential variance.
What defines this approach
Specialized, narrow-scope offerings with optimized playbooks: Real value and defensibility are typically unlocked when a provider identifies a narrow scope—a specific, well-defined problem or function that can be demonstrably and massively improved with AI. This focus is critical because:
Identifying such improvable functions and developing effective playbooks is a key capability in itself; achieving this across broader, more general functions is significantly more challenging.
As empirical findings to date suggest, simply layering AI onto existing broad processes (as some "rollup" strategies might attempt) often falls short of delivering significant productivity gains. True transformation typically requires a fundamental redesign of how work is done, which is most feasible within a narrow, provider-controlled scope.
Investing in a dedicated software layer around the LLM for a provider-managed workflow (e.g., specialized internal UIs, tailored integrations, automation scripts) typically yields a high return on investment. However, this level of impactful, specialized engineering is generally only feasible when the operational scope is narrowly defined; it becomes impractical or offers diminishing returns for overly broad, general-purpose applications.
AI integration & workforce management: The provider's operational ability to effectively integrate AI tools with their skilled human workforce to genuinely maximize productivity and quality is essential.
The pivotal role of domain expertise: This expertise is necessary for designing effective AI-augmented workflows, facilitating effective quality control, and ensuring the final output meets exacting client standards. This expertise becomes a significant competitive differentiator.
Provider control optimizes outcomes: A key advantage is that the provider designs and controls the optimal internal flow for how the AI is best used. There's no need to train end-users on the nuances of AI interaction (e.g., prompt engineering, watching for hallucinations), which removes a whole class of failure that no longer needs to be accounted for and gives the provider quite a wide margin of tolerable variance rates.
Providers have a strategic choice regarding transparency: whether or not to explicitly inform end-users that AI was involved in producing the service or deliverable.
The business dynamics closely resemble those of specialized, high-value third-party service providers. Brand reputation for quality, reliability, and deep expertise is paramount.
Subject to the amount of specialization, the addressable market for any single offering may be smaller, making a strategy of "dominating your pond" or achieving leadership in a specific niche essential for success.
Oh we should have mentioned, there is technically one more strategy available…

Final thought: constraint as catalyst
The unreliability of LLMs isn’t just a bug, it’s the foundational constraint that defines what’s worth building, how it should be built, and what defensibility even looks like in this new wave of AI-native products.
Indeed, one could argue that unreliability is the raison d'être for much of the application layer, it's the challenge that creates the opportunity for builders to deliver value.
Builders can’t wish the variance away. They have to choose where and how they handle it, and that choice is what determines whether their product is viable, differentiated, and durable.
The best builders aren’t trying to beat the model. They’re building systems that expect it to fail, and still work anyway.
Programming, Events, Content and More
🎙 Podcast Feature: Tech on the Rocks
Tune in to Verissimo’s Nitay Joffe, and Kostas Pardalis founder of Typedef, as they chat with tech geniuses on Tech on the Rocks—where hardware, cloud, and all things future-tech meet over a virtual drink!
Episode 18: Business Physics: How Brand, Pricing, and Product Design Define Success with Erik Swan - https://techontherocks.show/18
🚀 Founder & Community Programming
Reminder to check out our It’s All About Everything Series!
Portfolio Highlights

Celery recently announced a $6.25 million Seed round led by Team8. We wrote their first check and are excited to have participated in this latest round.
Celery is an AI-powered financial control platform that helps organizations catch costly payroll and revenue errors before they impact the bottom line. Designed for finance teams in high-volume, labor-intensive sectors like healthcare, Celery automatically audits thousands of records, flags policy violations, and uncovers unprofitable clients. By shifting from manual oversight to intelligent monitoring, Celery helps teams save time, improve accuracy, and take control of their financial data.

Receive helps small and medium-sized businesses unlock instant access to cash from pending customer payments. Instead of waiting days for transactions to clear, merchants receive a virtual card with immediate funds tied to their receivables. Repayment happens automatically once the original payment is processed, making the experience seamless and hands-free. Offered both directly and through payment providers, Receive gives businesses faster cash flow without disrupting existing systems.

Monto is streamlining enterprise billing by helping companies get paid faster with less manual work. Instead of navigating complex customer payment portals one by one, Monto connects to them all and automates the process of sending, tracking, and collecting invoices. By reducing friction in accounts receivable, Monto improves cash flow and frees up internal teams to focus on growth.

Trace Machina builds foundational software infrastructure for teams working on high-performance, safety-critical systems. It’s platform, NativeLink, is designed to accelerate complex code development, enabling faster builds, better simulation workflows, and significant savings on compute costs. It's especially well-suited for industries like aerospace, robotics, and advanced hardware, where reliability and speed matter most.
🎉 Events
Verissimo NYC Dinner
Incredible night with the Verissimo Ventures community in NYC—founders, LPs, and friends coming together to explore what’s ahead in AI, tech, and venture.
These moments remind us that meaningful relationships are at the heart of everything we’re building.
Grateful for the energy, insights, and shared vision around the table.



Who we are
Verissimo Ventures is a Pre-seed and Seed Venture Fund based in Israel and the US. We invest primarily in enterprise software companies and take a fundamentals-driven approach to early-stage investing. We work closely with founders to help them build the strongest, most fundamentally sound businesses with potential for explosive growth and a meaningful impact on the market.
We were founded in 2020 and are currently investing out of our $26M Fund 2.
Very good post, thanks for sharing. You tocuch on something important which you could fully explore in the future: user psychology around AI errors. People seem to have very different tolerance levels for AI mistakes versus human mistakes, which creates interesting product design challenges beyond just the technical reliability issues.
Thank you. This is one of the very few posts I have read that match my thinking. When ChatGPT3.5 was released back in late 2022 I, like many others I guess, was blown away. I was all in, but gradually came to realise the fundamental problem with hallucinations (errors). I thought it was just me. I thought it was a problem that would be correctable, but then at a random small scale event I managed to talk to an AI researcher who admitted the problem was not fixable it could only be improved. Since then I have felt like a voice in the wilderness. I could well be suffering from confirmation bias, but thanks again.