


Verissimo Monthly - February 2025
How AI Can And Will Shape The Future

Lots of updates and thoughts to share this month, so bear with us until the end!
Thoughts on Investing and Starting Up
It's been more than two years since ChatGPT exploded onto the scene—and our collective consciousness. Its pace of adoption has been among the fastest of any digital “app” in history, a particularly remarkable feat given that we are talking about the adoption of a new category of technology—the data suggests that U.S. adoption of generative AI has been faster than adoption of the personal computer and the internet.
This viral and shocking spread—the good folks at OpenAI famously launched ChatGPT as a low-key research preview—has led to an interesting dynamic: while most people “know” what generative AI is, many users’ experience is so limited and unproductive that they end up with a (very) false sense of what Large Language Models (LLMs) are currently “capable of” and where they are headed.
Here’s just one example:

Today we’ll explore:
The two main usage types
Which type most lends itself to investment
The killer app formula
The bottom line:
Large Language Models (LLMs) create value in two ways:
as knowledge repositories ("Genies")
as task executors ("Golems")
The greatest opportunities likely lie in workflow-integrated applications, where LLMs (a) enhance existing workflows or (b) unlock new workflows that were not previously possible.
Successful implementation typically requires domain expertise of the existing human-based workflow to select the best opportunities, insight to identify the creative improvements, and technical and product expertise to engineer the right solutions.
Let’s dive in…
I. The Two Main Usage Types
We find it useful to break down LLM utilization into two core usage archetypes: (A) Knowledge Interaction (it tells you things) and (B) Generative Tasks (it does things for you).
Let's explore these in detail…
A. Knowledge Interactions—The Genie
As the name would suggest this refers to interactions where the LLM provides users with information. This use case can span everything from learning a new skill from scratch and studying a new topic in depth (e.g., "What is General Relativity") to a quick lookup of how to solve a basic problem (e.g., “how do you accomplish X in Excel”). One incredibly useful example that I’ve personally used is uploading complex technical documents, academic papers, insurance forms, legal contracts, etc.—and having the LLM “break it down with you” as you read along. Try it, it will change your life. :)
Here we will cover three key points:
LLMs are incredibly knowledgeable
They suffer from important challenges
Nevertheless, they are useful even in their current form
1. LLMs are incredibly knowledgeable
Due to how they were trained, today’s LLMs contain the vast majority of humanity's accumulated knowledge, and are so capable at leveraging that knowledge that they are outgrowing the tests they are being evaluated against. We are literally running out of benchmarks to test new AI models on.
While benchmarks are certainly not a perfect measure (and most suffer from a number of known flaws), they are a good indicator of LLM’s capabilities, and feedback from real-world usage and exams both support this point.
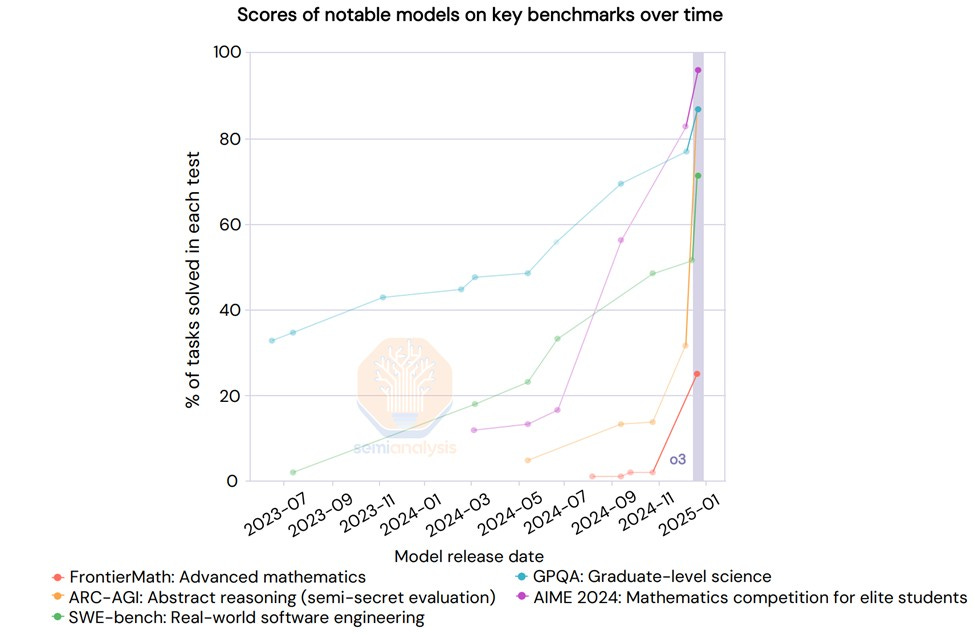

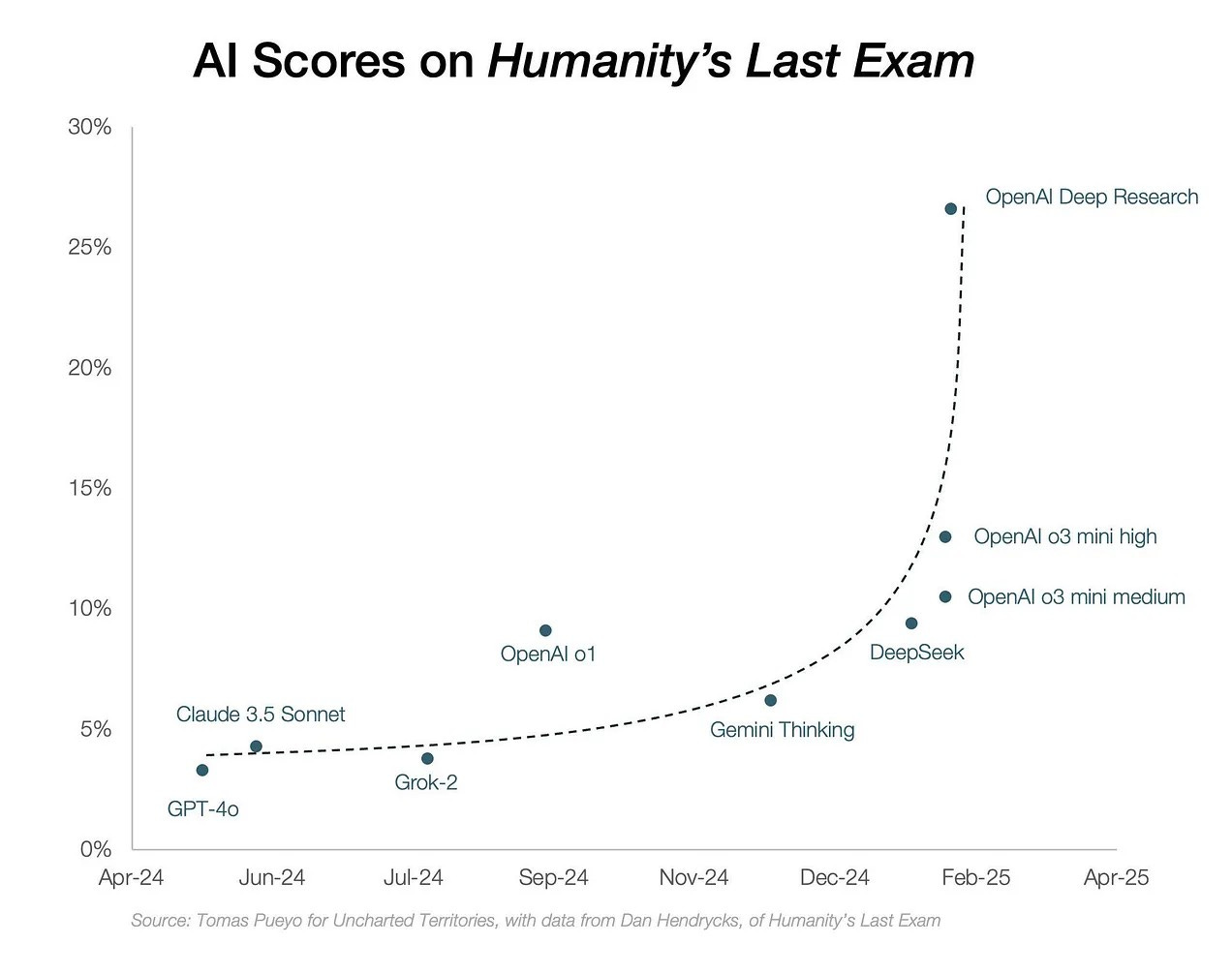
2. LLMs suffer from important challenges
The non-determinism problem (they’re not reliably consistent): LLMs possess remarkable capabilities but struggle with consistent reliability. This gap manifests when models demonstrate impressive knowledge in one instance but fail unexpectedly in similar scenarios. While an LLM might brilliantly explain quantum mechanics one moment, it could confidently misrepresent basic physics concepts the next—without any indication of reduced confidence.
The hallucination problem (they make stuff up): LLMs are fundamentally prediction engines that generate text based on statistical patterns rather than understanding truth. This leads to hallucinations—instances where models generate false information, fabricate references, or create entirely fictional narratives with complete confidence. This tendency to confabulate poses significant challenges in professional contexts where accuracy is paramount.
3. LLMs are useful even in their current form
There are a couple of stories that help illustrate how LLMs are useful even with these challenges:
A few months ago a particularly shocking story came to our attention. Some kid used a LLM to build a nuclear fusor in his bedroom – with zero hardware experience – in a couple of weeks.
Another, more boring yet perhaps more illustrative case is a study at Harvard which compared physics students who were assisted by an AI tutor against students who participated in a more “traditional” human-led, active learning classroom, and found that: “when students interact with our AI tutor, at home, on their own, they learn more than twice as much as when they engage with the same content during an actively taught science course, while spending less time on task”—while feeling more engaged and motivated to boot.
More generally, the reason people are finding so much success is twofold:
Models are getting better - hallucinations are increasingly not a problem for knowledge-based tasks.
Users are becoming more skilled at working with their strengths and managing their weaknesses.
With regards to hallucinations specifically, our general sense here (supported by anecdotal experience and observation—and corroborated by other informed observers) is that that the typical hallucination one imagines, the kind where the model makes things up is becoming less and less common—and that a savvy user learns to recognize what types hallucinations are likely occur, when and how they are likely to occur, and they best ways to mitigate against them.
The inflection point seemed to occur during 2023 when a plurality of users became capable of deriving meaningful value and the incredible advancements that have since followed have further raised their reliability, usability and raw capability.
Adam Brown of DeepMind, and a theoretical physicist at Stanford, summarized the current state of Knowledge Interactions well:
The other thing that they're extremely useful for now that they were useless for before is just as a tutor. There is a huge amount of physics that a physicist would be expected to know that has already been done. No human has ever read the whole literature or understands everything, or maybe there isn't even something that you feel you should understand, or you once understood that you don't understand.
I think the very best thing in the world for that would be to phone up a colleague, if you knew exactly who to phone, they'd probably be able to answer your question the best. But certainly, if you just ask a large language model, you get great answers, probably better than all but the very best person you could phone. They know about a huge amount, they're non-judgmental, they will not only tell you what the right answer is, but debug your understanding on the wrong answer.
So I think a lot of physics professors are using them just as personal tutors. And it fills a hole because there are personal... If you want to know how to do something basic, it's typically very well documented. If you want to know advanced topics, there are not often good resources for them.
LLMs have tremendous utility in the Knowledge Interaction capacity as either teachers or oracles (give a fish or teach to fish). The main thing now holding back greater real-world impact is user creativity, awareness, and skill.
B. Generative Tasks—The Golem
As this name suggests, this refers to having an LLM do something useful. There are three basic categories of Tasks that LLMs can do:
Language
Data
Processes
In this section, we will define each one and discuss its impact
1. Language
These are the most well-known use cases (e.g., summarization, first drafts, translations, Q&A, etc.). Virtually all of these use cases are “horizontal” in nature - i.e., they cut across industries - and hence are getting incorporated into seemingly every existing software tool. Despite the widespread adoption of this form, it adds relatively little value compared to the other types (with the exception of code).
2. Data
LLMs enable users to query data, enabling executives, employees, and customers to interact with relevant information in useful ways. The basic idea here is giving an AI access to a quantitative knowledge base (internal or otherwise). Doing so unlocks the ability to query a company's (proprietary) unstructured data in natural language and enables everything from automated customer support to a transformation in internal visibility (BI+). While we do believe that the enterprise knowledge bot offerings will deliver real value—the space already has a number of serious players with real traction—we suspect that there is somewhat of a ceiling here and that in the long run this category will account for a comparatively small fraction of the overall Generative AI market.
3. Processes
Users are able to enhance processes by interweaving LLMs into them. These are the most useful Tasks that LLMs can accomplish. They tend to be highly context specific, usually verticalized, non-obvious, and paradigmatically new in that they require real creativity and care in their design. This third category is where a lot of the “power users” are gaining their productivity increases, and perhaps more interestingly (and scalably) where most of the (very few) third party killer apps are being created. In practice, domain expertise/real experience with the workflow is usually required for success. Some eclectic real world examples include: historical text transcription and analysis, “help me beat a car rental damage claim,” or “see what CEOs said about the labor market in their conference calls.”
II. Process-based “Tasks” lend themselves most to investment
A. Knowledge Interactions (“The Genie”) do not easily lend themselves to investment.
Ultimately, we think Knowledge Interactions will not be the main investment space.
The question of investability of third party apps in the Knowledge Interaction space is quite a complicated one (and worthy of its own deepdive) and the answer varies based on specific context, but high level, we believe a few things are true here:
Most of the “tricks” that are used to help with hallucinations don't solve the fundamental problem—enabling you to blindly trust the AI’s output, and are often no better a mitigation strategy than a quick follow-up Google search
The mechanisms to try to solve the problems tend not to scale beyond their immediate use case. Inevitably the vast majority of potential LLM interactions (literally most of humanity's cumulative knowledge stores) will simply never be “reached” by tools—and this holds for most potential UI/UX improvements as well.
We expect most of the value creation here to accrue to the big model providers directly, and not third party applications—though there will be exceptions of course (AI-powered TurboTax?). Tools may be necessary now, but they won’t be in the future. The Genie use case is in most ways the core of what LLMs are, and so, as intrinsic capabilities continue to increase (which we are optimistic about) so too will the LLM’s value itself.
B. Generative Tasks (“The Golem”)
Language and Data “tasks” suffer from key weaknesses when it comes to building investable products. As noted, the language tasks are of relatively little use when compared to the other categories, and the data tasks space is already saturated. In contrast, process tasks don’t suffer from these weaknesses, and therefore will continue to be the most investable opportunities.
Process tasks have outsize impact and are limited in their current development. Significantly, they also require third-party tools to deliver their maximal impact, as most users are not able to reach maximal impact in their private use. There are at least three key reasons why this is so:
Improved UI/UX: APIs can streamline processes beyond the more basic interface that LLMs currently allow (e.g., chatting, copying-and-pasting).
Expanded capabilities: LLMs are pretty bad at complex, real-world open ended reasoning—and as such are quite bad at thinking at an abstract or high level. They can execute well for narrowly defined tasks but if you try to give it real responsibility like an AI software engineer or AI scheduling assistant, they will quickly go off the rails. Hard-coding a reasoning layer provides a possible solution.
Better error-checking: Tools can catch or otherwise mitigate hallucinations and non determinism at a level that humans cannot. Here too a coded reasoning layer (rules, plain old software) to manage this variability offers a possible solution—indeed this is an absolute necessity for the vast majority of LLM-powered apps (when one does choose to go the tool route), as lack of certainty about how your application will behave (i.e., the chance that your system will simply invent data/do something unexpected) is a feature fundamentally incompatible with mature, real-world usage.
III. The Killer App Formula
The most successful apps tend to democratize the value of LLMs, even beyond what power-users can achieve because of digitization and automation. Most killer LLM-powered apps we've seen seem to follow the same basic structure:
Select: Take an existing workflow—usually one that is some combination of complex, time-consuming and annoying.
Diagnose: Identify how timely and specific calls to a LLM carefully interspersed throughout its lifecycle can improve it.
Engineer: Construct an engineering layer that authors the workflow—a UI that guides users to work the way you need them to—and a hard-code a reasoning layer that calls the LLM at the right time and in the right way—and voilà, you get magic.
A great example of a killer app following our formula is perhaps the most popular LLM-powered app we know of, Cursor the AI powered integrated development environment (or code-editor). The genius of Cursor is two-fold: (1) understanding that LLMs can give extremely useful coding/formatting suggestions that can incorporate context – a new dimension of autocomplete, and (2) understanding that UX is what will make or break the value proposition here—and nailing it.
Looking into the future
We believe that LLMs will have the major economic impact many are forecasting (though we can quibble about magnitude, and we don't agree with everyone). A major component of their value will be delivered via third party tools (the “Application Layer”) that productize these magic use cases, and that this category will expand over time to include entirely new workflows centered around this magic LLMs can do.
Even though LLMs are improving, they’re not getting better in the three main ways covered above that would make tools obsolete (i.e., enhanced UI/UX, expanded open-ended reasoning, and reliable error-checking). Going forward, we will be looking for products that augment workflows and founders that are likely to identify these most beneficial use cases.
A version with footnotes and sources can be found here.
Programming, Events and More
We are super excited to have kicked off our “It’s All About Everything” Founder Series, with our first Expert Sessions and Zone of Genius Cohorts beginning next week. You can learn more here: https://verissimo.vc/its-all-about-everything-founder-series
Last week, we hosted an incredible evening at the Tasting Room in Tel Aviv, bringing together founders, investors, and key players in the tech ecosystem for a night of great conversations over wine and cheese. It was amazing to see so many familiar faces and new connections being made.





Stay tuned for more gatherings soon! 🚀🍷
🎙 Podcast Feature: Tech on the Rocks
Tune in to Verissimo’s Nitay Joffe and Kostas Pardalis, founder of Typedef as they chat with tech geniuses on Tech on the Rocks—where hardware, cloud, and all things future-tech meet over a virtual drink!
Episode 13: Yaron Hadad - From black holes to AI in mathematics: AI Innovation in Mathematics and Health - https://techontherocks.show/13
Episode 14: David Jayatillake - Semantic Layers: The Missing Link Between AI and Data - https://techontherocks.show/14
Portfolio Highlights

PromptLayer recently announced a $4.8 million Seed raise led by ScOp Venture Capital. We participated alongside Stellation Capital and several Angels.
PromptLayer is a centralized prompt management platform designed to streamline the deployment of prompts in LLM-powered applications. PromptLayer's platform enables teams to store, organize, iterate, and assess prompts in a single location, collaboratively. PromptLayer’s easy-to-use interface empowers non-technical domain experts to play a key role in the development of AI applications.

Flare’s software platform simplifies the delivery of complex professional services while addressing consumers' expectations of ease and clarity throughout the process. Their platform automates time-consuming administrative tasks and streamlines client communication, freeing lawyers to concentrate on their core expertise—practicing law.
Who we are
Verissimo Ventures is a Pre-seed and Seed Venture Fund based in Israel and the US. We invest primarily in enterprise software companies and take a fundamentals-driven approach to early-stage investing. We work closely with founders to help them build the strongest, most fundamentally sound businesses with potential for explosive growth and a meaningful impact on the market.
We were founded in 2020 and are currently investing out of our $26M Fund 2.